A Series of Unfortunate Agents
Agents introduce a new category of enterprise risk that doesn’t fit neatly into existing frameworks. This piece proposes a structured taxonomy: hallucination propagation risk, tool misuse risk, cascading failure risk, data exfiltration via tool chains, and unintended autonomy escalation. Each risk category grounded in real operational scenarios from enterprise platform work.
Introduction
For the first nine years of my career, I lived in the murky world of fraud, malware, spam, and abuse. Working on these problems at scale gives you a certain kind of paranoia — a finely tuned sense for risks, attack vectors, and the myriad ways in which malicious actors can harm unsuspecting users. You learn to think like an adversary, not because you want to, but because you have to.
When these risks go uncontrolled, the consequences are tangible and severe. Users get harmed. Reputation takes a hit. Business dries up. The risk of rampant fraud, malware, spam, and abuse was always top-of-mind at Google — reputational, financial, regulatory. Google has built a formidable reputation for being a bastion of, and industry leader in, anti-abuse protections. This didn’t happen by accident. It came about in no small part due to their in-depth understanding of risk factors, and a governance and compliance function that is applied top-to-bottom across the entire company.
This experience has made me deeply appreciative of the role that risk management plays in the successful functioning of an enterprise, and its continued utility to society. It’s the kind of appreciation that’s hard to develop from the outside — you really need to see what happens when risk goes unmanaged to understand why it matters so much when it is.
So when I look at the current wave of agentic AI systems being deployed across enterprises, my fraud-and-abuse radar lights up. Not because agents are inherently dangerous, but because they introduce genuinely novel risk categories that most organizations aren’t yet equipped to reason about. That’s what this post is about.
What is Risk?
At its core, a risk is anything that can impact an enterprise’s ability to continue to exist as a going concern. That might sound dramatic, but it’s the right framing. While the most obvious types of risk are financial and business-related, there are other non-monetary risks that matter just as much: regulatory, reputational, and talent-related risks can all be existential in the right (or wrong) circumstances.
There are very few true black-swan risks — the kind that come out of nowhere and knock you flat. Most risks are far more insidious. They’re death by a thousand cuts: small, compounding issues that erode the business gradually until someone looks up and wonders how things got so bad.

Here’s the thing: any activity a business engages in has risks involved in some form. Launching a new product? Risk. Entering a new market? Risk. Hiring a new team? Risk. Standing still and doing nothing? Also risk. It’s important to understand the risks involved in running a business in order to mitigate them sufficiently — not to eliminate risk entirely (that’s impossible), but to manage it deliberately.
Risks vary depending on a number of factors. No two businesses may have the same set of risks, although they might overlap significantly. As a result, it’s important for businesses to understand which risks are worth addressing and which risks are worth accepting. This forms the enterprise’s risk strategy — the deliberate choices about where to invest in mitigation and where to tolerate exposure.
The risk strategy then informs the policies that must be enforced within the enterprise in order to mitigate the identified risks. But here’s the catch: risk mitigation is only as good as enforcement. A policy that exists on paper but isn’t enforced is worse than no policy at all — it gives you a false sense of security. Therefore, a compliance function must exist to ensure that the risk mitigations are functional and are leading to actual compliance with the policy. And of course, the policy must be reviewed periodically to adapt to emerging risks, because the threat landscape doesn’t stand still.
This forms what’s known as GRC — the Governance-Risk-Compliance pillar, a foundational part of many enterprises’ risk management practices. It’s worth noting that there are many interdependencies and co-occurrences between risks. Sometimes there are temporal dependencies — one risk materializing can trigger or amplify another. Understanding these relationships is part of what makes risk management an art as much as a science.
Enterprise Risk specifically refers to the form of risk that arises from the enterprise itself — for instance, insider risk, operational failures, or systemic vulnerabilities in internal processes. It’s the risk you create by existing and operating, as opposed to purely external market or environmental risks.
Risk Management — A Practical Example
Let’s make this concrete with a real-world example from the software world: Software Bills of Materials (SBOMs) and the SLSA framework.
The risk being mitigated here is supply chain compromise — the possibility that a malicious actor introduces tampered code, dependencies, or artifacts into your software supply chain. If you’ve been paying attention to incidents like the SolarWinds attack or the XZ Utils backdoor, you know this isn’t theoretical. The consequences of not mitigating this risk range from deploying compromised software to your customers, to regulatory penalties, to complete loss of trust in your product.
So what’s the mitigation? The first line of defense is the SBOM — a complete, machine-readable inventory of every component, library, and dependency that makes up a software artifact. Think of it as a nutritional label for software. When a vulnerability like Log4Shell drops, organizations with SBOMs can answer “are we affected?” in minutes instead of weeks. Without one, you’re left scrambling through build logs and hoping your dependency tree doesn’t have any surprises. SBOMs make the invisible visible — you can’t secure what you can’t see.
But knowing what’s in your software is only half the battle. You also need to trust how it was built. That’s where SLSA (Supply-chain Levels for Software Artifacts) comes in. SLSA builds on the transparency that SBOMs provide and goes further by establishing provenance and integrity guarantees for the entire build process. Where an SBOM tells you “this artifact contains components X, Y, and Z,” SLSA tells you “this artifact was built from this exact source, by this build system, and nothing tampered with it along the way.” It defines a series of levels (L0 through L3) that provide increasing assurance — from basic provenance documentation at L1, to a hardened, tamper-resistant build platform at L3. Together, SBOMs and SLSA give you both the “what” and the “how” of your software supply chain.
The policy that flows from this is straightforward: all software artifacts deployed to production must meet a minimum SLSA level. Builds must be reproducible. Dependencies must be pinned and verified. Provenance attestations must be generated and stored.
Enforcement happens through automated tooling in the CI/CD pipeline. You can’t deploy an artifact that doesn’t meet the policy requirements — the system simply won’t let you. This is the ideal form of enforcement: automated, consistent, and hard to circumvent.
Compliance is measured through regular audits of the build pipeline, verification of provenance attestations, and monitoring for policy violations. Dashboards track which teams and services are compliant, and which need remediation.
This is a clean example of the GRC cycle in action: governance (the policy), risk (supply chain compromise), and compliance (automated enforcement and measurement). Keep this pattern in mind as we move into the less well-charted territory of agentic AI risk.
Risk Taxonomy — Organizing Risk
A risk taxonomy is a structured approach to organizing and reasoning about enterprise risk. It takes into consideration all the dimensions of risk that an organization faces and methodically categorizes them into a coherent framework. Think of it as the periodic table of risk — a systematic way to ensure you’re not missing something important.
A risk taxonomy is derived by assessing and evaluating the different dimensions of risk and categorizing them methodically. Thankfully, enterprises don’t have to start from scratch every time. There are published and well-vetted risk taxonomies that provide a solid starting point. The risk taxonomy helps companies evaluate the relevance and severity of each risk category to their specific business, which can then be used to guide policies and strategy.
Most companies over time develop their own risk taxonomy that’s fine-tuned to their industry, business, location, market, and customer segment. A fintech company in Singapore will have a very different risk profile than a manufacturing company in Ohio, even if the high-level categories overlap. The risk taxonomy is typically owned by the company’s Risk function, which defines the Governance, Risk, and Compliance strategy for the company.
The common, or Level 1, risk categories that appear in most enterprise taxonomies are:

- Operational: Failures in internal processes, systems, or personnel. This is the “things going wrong in the day-to-day” bucket.
- Strategic: Risks affecting business goals, strategy, or market position. Making the wrong bet on a market or technology falls here.
- Financial: Risks from market fluctuations, credit, or liquidity. The classic risk category that keeps CFOs up at night.
- Compliance: Legal, regulatory, and ethical violations. Getting on the wrong side of a regulator is expensive in every sense of the word.
- Reputational: Damage to brand or reputation. In the age of social media, this can materialize faster than any other risk category.
So what are the benefits of having a well-defined risk taxonomy? Several:
- Consistency: It standardizes risk reporting across the organization. Everyone is speaking the same language about the same things.
- Improved Communication: It ensures all stakeholders use the same terminology. When the security team says “operational risk,” the board knows exactly what they mean.
- Effective Mitigation: It links risks to specific controls and owners. Every identified risk has someone responsible for managing it.
- Informed Decision-Making: It provides a clear picture of the organization’s risk profile, enabling leadership to make strategic decisions with eyes wide open.
I won’t get into the process of how to create a risk taxonomy here — that’s a deep topic on its own. Instead, let’s switch gears and talk about the specific risks that agents introduce, and why they deserve their own dedicated attention.
Agentic Risk — What’s Different?
Agents bring genuinely new forms of risk that did not exist before. Some of the key ones:
Risks due to non-determinism. This is arguably the single biggest new risk dimension that agents introduce. Traditional software is deterministic — given the same inputs, you get the same outputs. Agents break this contract fundamentally. Non-determinism introduces a cascade of risks: hallucinated details that look plausible but are fabricated, incorrect or inconsistent interpretation of user requests, erroneous tool calls that perform the wrong action, and the compounding of errors through longer trajectories. The longer an agent runs autonomously, the more these small deviations can compound into significant failures.
Generation of harmful content. Agents can potentially generate harmful content if insufficient controls exist. The recent controversy about Grok generating sexually explicit images of real people, and the very real regulatory consequences of that oversight, is a stark example of such a failure. This isn’t just a reputational risk — it’s a legal and compliance risk that can result in fines, lawsuits, and regulatory action.
Biased decisions. Decisions made autonomously by agents may carry implicit or explicit bias that impacts people. This exposes the enterprise to both reputational and legal risk. When an agent is making decisions about loan approvals, hiring recommendations, or customer service escalations, even subtle biases can have outsized impacts on individuals and communities — and by extension, on the organization deploying those agents.
Unauthorized actions. Agents may, through intentional or unintentional means, act in potentially harmful ways: performing unauthorized financial transactions, sending unauthorized communications, denying service, or starving resources. Agents acting without human approval or oversight can cause direct financial losses and open up the organization to compliance and reputational risks. The more capable the agent, the more damage it can do when it goes off the rails.

Malicious steering. Agents act on large amounts of unstructured data, and it’s difficult to control what goes into them. It’s possible to poison the context so that the agent is guided to do something unwanted, through techniques like prompt injection. An attacker doesn’t need to compromise your systems — they just need to craft the right input to redirect your agent’s behavior.
This is a rich and rapidly evolving area of research, with a number of frameworks emerging to help organizations think about these risks. I expect that eventually a formal, industry-wide taxonomy will crystallize and be adopted more broadly. In the meantime, let me walk through a few of the frameworks that exist today. It should be clear that there isn’t a single standard that (as of this writing) everyone has converged on — and that’s okay. Organizations should feel empowered to do their own research and establish a taxonomy that makes sense for their particular business and situation.
I’ve included below the outlines of a few such emerging taxonomies that explore different aspects of agentic risk. You’ll see that a lot of the risk categories & sub-categories overlap; this is expected. I’m intentionally focusing only on risk types; refer to the source material if you’re interested in more details and mitigations.

Agentic Safety Taxonomy
This is based on the work of Nöther, et. al, where they define a taxonomy of harms and a benchmark for measuring agents’ compliance. While I suspect the benchmark isn’t easily generalizable across all domains and deployment contexts, the taxonomy itself still adds considerable value as a thinking framework. They classify the harms as follows:

Agentic AI Security: Threats, Defenses, Evaluation, and Open Challenges
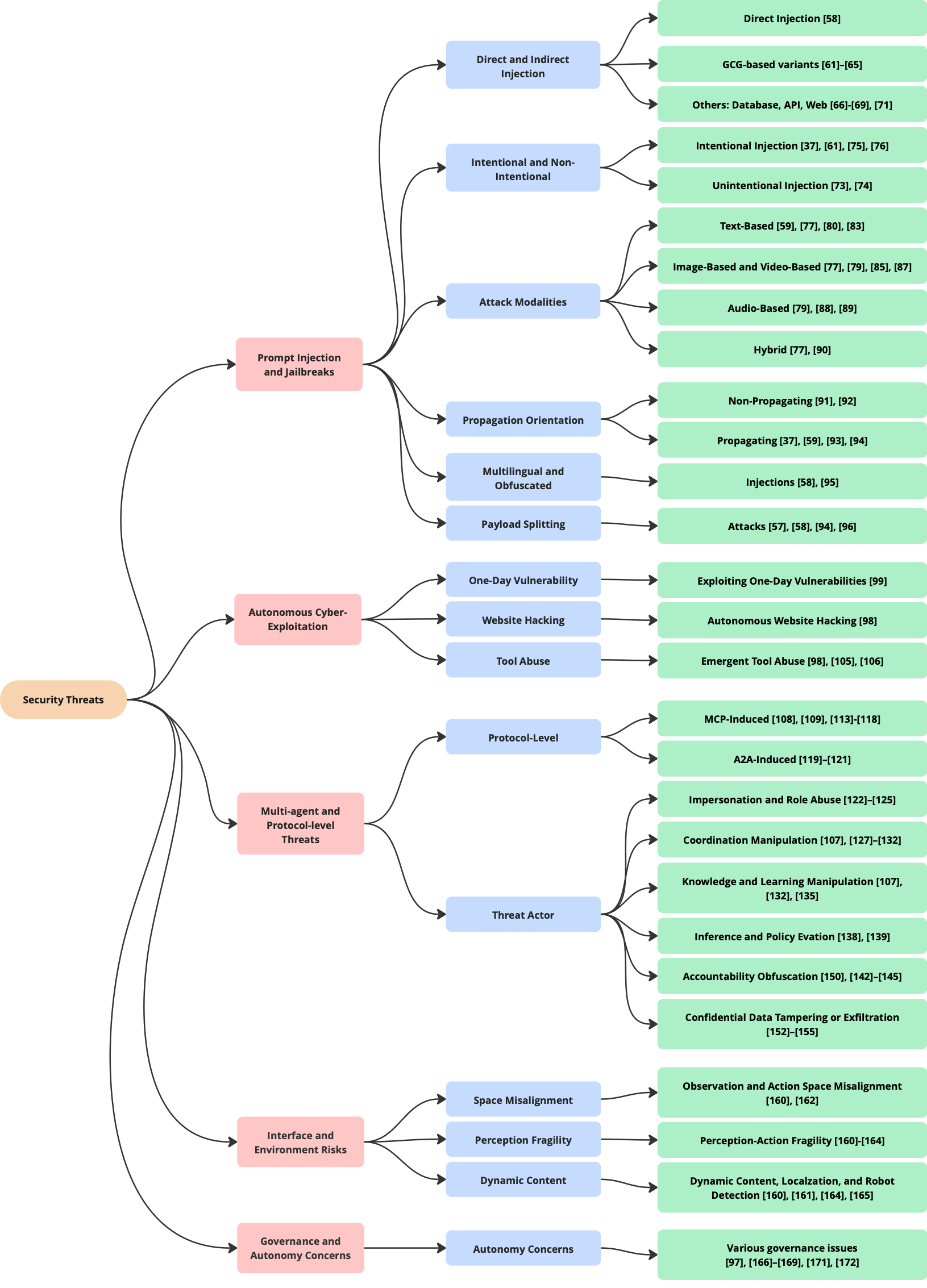
This paper, by Chhabra, et. al, takes a different angle. It focuses specifically on Security Vulnerabilities and Risks, dividing the threats into the following categories: Prompt Injection and Jailbreaks, Autonomous Cyber-Exploitation and Tool Abuse, Multi-Agent and Protocol-Level Threats, Interface and Environment Risks, and Governance and Autonomy Concerns. Unlike the previous paper, this work focuses exclusively on Security Risks and takes a more tactical rather than strategic approach to its categorization. If Nöther et. al gives you the “what could go wrong” at a high level, Chhabra et. al gives you the “how an attacker would make it go wrong” at an operational level.
The OWASP Agentic AI Threats & Mitigations
The OWASP Agentic AI Threats & Mitigations builds on other OWASP guidelines and standards, especially those for LLM Applications and Generative AI, APIs, and the overall set of threats that OWASP considers to be critical. If you’ve worked in web application security at any point in your career, you’re probably already familiar with OWASP’s approach — they have a knack for distilling complex threat landscapes into actionable, prioritized lists. Their agentic AI work follows that same tradition, and benefits from the broader OWASP community’s experience with application security. In the below diagram, I have specifically identified top-level risk categories - these aren’t explicitly called out in the OWASP paper.

EnkryptAI Risk Taxonomy
EnkryptAI, an AI security platform company that helps enterprises detect, remove, and monitor risks like hallucinations, privacy leaks, and misuse across the AI development lifecycle, has published a risk taxonomy that builds on top of the OWASP threat categorization and adds its own classification layer. Again, this provides a flavor of the kind of risk taxonomy that’s possible for agents, and demonstrates how organizations can take existing frameworks and extend them to suit their specific needs.

Conclusion
If there’s one thing I hope you take away from this piece, it’s that risk taxonomy for Agentic AI is still very much evolving. This is a fast-moving space, and the frameworks I’ve outlined above are snapshots of the current thinking — not final answers. New risk categories will emerge as agents become more capable and are deployed in more contexts.
It’s critical for organizations to be aware of, and invest in mitigations for, the novel risks introduced by Agentic AI. These aren’t theoretical concerns — they’re practical realities that teams deploying agents are encountering today. As agents become more prevalent and widely adopted, the potential for damage due to unmitigated risks only goes up. The time to start building your risk management muscle for agentic systems is now, not after the first incident.
That said, I want to be clear: none of this should be taken as an argument against investing in agents. The benefits of agentic AI are real and substantial. But those benefits are best realized by organizations that approach deployment with a clear-eyed understanding of the risks involved. A comprehensive, organization-wide risk strategy is essential to ensure that businesses can continue to economically benefit from Agentic AI without exposing themselves needlessly. The goal isn’t to avoid risk — it’s to manage it deliberately, just like we do with every other dimension of enterprise risk.
